GIT_1 : (not so) Basic Concepts
by Lord_evron
If you are a programmer and your team consist of a total number of people more or equal than 1, then you are probably using GIT. Git can be quite complex for advance use cases, so if you never used “rebase” command or if you never squashed any of your commits or if you never heard about forks, then you are probably not utilizing it properly. This guide aims to introduce and explain these concepts to help you leverage Git more effectively. Ah before we start, I assume that you are familiar with basic git terminology.
One common way for people to use git is to just use one common repo, with only one “master” branch.
the team members (usually only few) pull from the origin/master and push their changes to the origin/master.
This is the easiest workflow and also the wrong one, because everyone is pushing whatever sh*t with no control.
Consider a developer making minor changes, such as setting a variable: VAR="Hello".
They might inadvertently create a series of commits with meaningless messages like changing var to HELO,
reverting var to ORIGINAL, and changing var to HELLO. These individual commits,
along with potential merges from other developers, will clutter the ‘master’ branch history,
making it difficult to understand the development process and track down the source of issues.
Not a good workflow…A more structured approach is essential for maintaining a clean ‘master’ branch. While a single ‘master’ branch might be feasible for small teams of highly skilled Git users, it still carries inherent risks. Even with experienced developers, direct pushes to ‘master’ can lead to unintended history rewrites, which should be avoided. Additionally, this approach lacks a formal code review process. To incorporate code reviews and ensure a more robust workflow, we need to introduce additional mechanisms. This will be explored in detail in the next article. For now, let’s begin by establishing a foundational understanding of some essential Git concepts.
Basic Git Concepts and Pull Requests.
Surprisingly, even experienced programmers often lack a deep understanding of fundamental Git concepts. While they may be familiar with a few commands and have used Git for years, they may not fully grasp the underlying mechanics. For example, consider these basic questions:
- Can I have remote repositories other than “origin”?
- How do I pull code from multiple online repositories?
- What is a detached HEAD state and how does it occur?
If you’re already comfortable with these concepts, feel free to proceed to the next article.
Alternatively, if you ask me those questions, I would usually answer with a “RTFM”. However, is Easter, and we are all “good”… so lets continue..
Understanding Git Remotes and Branches
A common misconception is that multiple developers working on the same project share a single, unified set of files. However, this is not the case. When you clone a Git repository, you create a complete, independent copy of that repository at a specific point in time. This includes all branches and their respective histories.
The “origin” Remote:
By default, the URL of the repository you cloned from is assigned the name origin. You can verify this using the command git remote -v.
This “origin” acts as a reference point for your local repository.
Local branches are typically configured to track their counterparts on the remote repository. For instance, the local branch
dev/feat1 automatically tracks the remote branch origin/dev/feat1.
This means that commands like git pull and git push will interact with the corresponding remote branch by default.
When you create a new local branch (e.g., “dev/feat2”) and attempt to push it to the remote, Git will inform you that no remote branch exists for it.
The suggested command, git push -u origin dev/feat2, establishes a tracking relationship between the local branch and a newly
created remote branch with the same name.
While it’s common practice to use the same names for local and remote branches, this is not a strict requirement.
You can configure a local branch to track any remote branch, even if they have different names.
However, this can lead to confusion and is generally discouraged.
The default “origin” remote can be renamed using git remote rename command. So git remote rename origin pedro, will rename origin to pedro,
and allows you to do git pull pedro master This allows you to use a more descriptive or personalized name for your remotes.
When you fork a repository on platforms like GitHub or GitLab, you essentially create a personal copy of that repository on your account. This independent copy allows you to experiment, make changes, and contribute to the original project without directly modifying the main repository.
- After cloning your fork, your local repository’s “origin” will point to your fork.
- To interact with the original repository (often referred to as “upstream”), you need to add it as a new remote using
git remote add upstream <URL of original repository>.
then you can for example incorporate changes from the original repository to your fork by:
- Pulling from upstream:
git pull upstream master(fetches changes from the original repository’s “master” branch) - Push to your fork:
git push origin master(pushes the updated code to your fork’s “master” branch)
Important Note: When working with multiple branches, it’s crucial to be mindful of the current local branch context.
For example, issuing git pull upstream master while on the local branch dev/feat1 will merge the upstream “master” branch into your local dev/feat1
branch and not in your local master branch!
Now lets suppose you pushed some new code on dev/feat2 and you want it to appear in the original repo on branch master… how normally is done?
Well first you push the code to your remote fork. Then from there using the GUI open a Pull Request (sometimes called merge request) into the original repo. This is basically a request to merge your code changes with the one in the original repo. Now, few clarification. The pull request can be opened from any branch to any branch. Ideally you could push your changes to your fork master branch and then open a PR to the original master branch from your fork master. However, this is not considered good practice. Usually you have a branch in your fork, and then you open a PR from that branch to the original master. once is approved, you can sync again your fork master with the new original master… We will discuss this more in details in the next article.
Detached Head
Last concept that i want to clarify is the HEAD and commit hash. The HEAD in Git is a pointer that always points the currently checked-out commit.
When you switch branches using git checkout dev/feat1, the HEAD pointer moves to the most recent commit of the dev/feat1 branch.
Subsequent commits on this branch will be added to its history, and the HEAD pointer will automatically advance to point to the newest commit.
Git’s checkout command also accepts a commit hash as an argument (e.g., git checkout 67ce4). This directly checks out that specific commit.
However, since a commit can belong to multiple branches, Git cannot definitively determine which branch to associate with it.
This results in a “detached HEAD” state
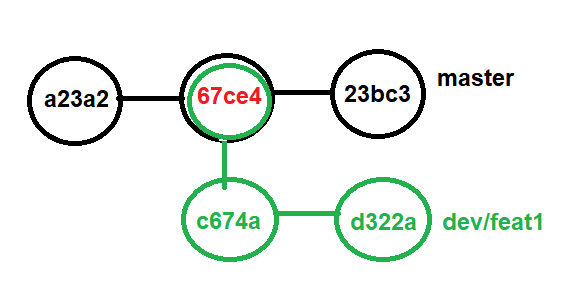
For example the commit 67ce4, in the diagram, is shared by two branches. If you use the command git checkout 67ce4 to check out this specific commit,
Git will successfully locate and check out that commit. However, since this commit belongs to multiple branches,
Git cannot definitively determine which branch you intend to be on.
Consequently, the HEAD pointer, which normally tracks the current branch, remains unattached. This state is referred to as a “detached HEAD” state.
Implications of a Detached HEAD
- Isolated Commits: Any new commits made while in a detached HEAD state will not be associated with any branch. These commits will exist independently, effectively “dangling” within your repository’s history. This can make it difficult to track, manage, and integrate these commits later.
- Submodule Challenges: Working with submodules can be particularly problematic in a detached HEAD state. Commands like git submodule init often check out specific commits within the submodules, which can further complicate the situation and potentially lead to additional detached HEAD states within the submodules themselves.
Exiting a Detached HEAD State
There are two primary ways to resolve a detached HEAD state:
- Create a New Branch: The most recommended approach is to create a new branch from the current detached HEAD state:
git checkout -b new_branch_nameThis creates a new branch (e.g., “new_branch_name”) and moves the HEAD pointer to the tip of this newly created branch. You can then continue working on this branch and push your changes as usual.
- Check Out Another Branch: Alternatively, you can switch to another existing branch:
git checkout <existing_branch_name>This will move the HEAD pointer to the tip of the specified branch, effectively exiting the detached HEAD state.
If any of these basic concepts is not clear, then before you move to the next article you really need to RTFM.
tags: code - git - technology